Overview
Running multiple Bifrost nodes provides high availability, load distribution, and fault tolerance for your AI gateway. This guide covers the recommended approach for deploying multiple Bifrost nodes in OSS deployments.OSS vs Enterprise
How It Works
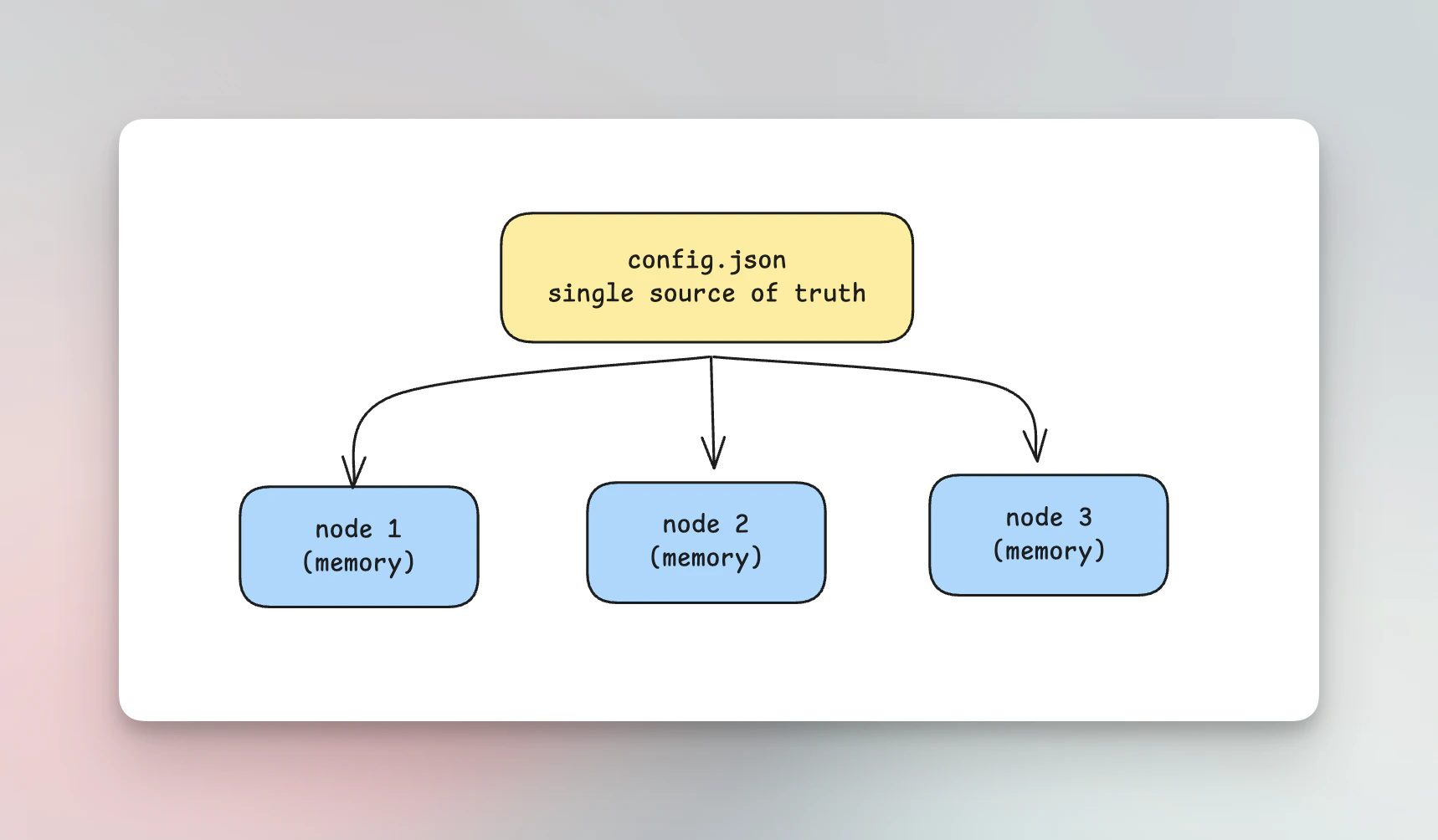
All configuration in Bifrost is loaded into memory at startup. For OSS multinode deployments, the recommended approach is to useconfig.json without config_store enabled.
config.json as Single Source of Truth
When you deploy without config_store:
- No database involved -
config.jsonis the only configuration source - Shared file - All nodes read from the same
config.jsonfile - Identical configuration - Since the source is shared, all nodes automatically have the same configuration
- No sync needed - The shared file itself ensures consistency
Why not to use config_store for Multinode OSS?
Using config_store (database-backed configuration) with multiple nodes in OSS creates a synchronization problem:
- Config changes are local - When you update configuration via the UI or API, it updates the database and the in-memory config on that specific node only
- No propagation mechanism - Other nodes don’t know about the change; they keep their existing in-memory configuration
- Nodes become out of sync - Different nodes end up with different configurations
- Restart required - You’d have to restart all nodes after every config change to bring them back in sync
Enterprise Solution
Bifrost Enterprise includes P2P clustering with gossip protocol that automatically syncs configuration changes across all nodes in real-time. See the Clustering documentation for details.Setting Up Multinode OSS Deployment
Example config.json
Create aconfig.json without config_store or logs_store:
If you use PostgreSQL for
logs_store, ensure the target database is UTF8 encoded. See PostgreSQL UTF8 Requirement.Notice
config_store is disabled. This ensures all configuration comes from the file only.Kubernetes Deployment
Use a ConfigMap to share the same configuration across all pods:Docker Compose
Share the configuration using a bind mount:Bare Metal / VM Deployment
For bare metal or VM deployments, distribute the configuration file using:- NFS mount - Mount a shared NFS directory containing
config.json - rsync - Sync the config file from a central location to all nodes
- Configuration management - Use Ansible, Chef, or Puppet to deploy identical configs
Updating Configuration
To update configuration in a multinode OSS deployment:-
Modify the shared
config.jsonfile- Update the ConfigMap (Kubernetes)
- Edit the shared file (Docker Compose / bare metal)
-
Restart the nodes
- Rolling restart is supported - nodes can be restarted one at a time
- Each node picks up the new configuration on startup
Kubernetes Rolling Restart
Docker Compose Restart
Best Practices
Use Environment Variables for Secrets
Never put API keys directly inconfig.json. Use the env. prefix to reference environment variables:
Load Balancer Configuration
Always put a load balancer in front of your Bifrost nodes:- Kubernetes: Use a Service with
type: LoadBalanceror an Ingress - Docker/VMs: Use nginx, HAProxy, or a cloud load balancer
Health Checks
Configure health checks to ensure traffic only goes to healthy nodes:- Liveness endpoint:
GET /health - Readiness endpoint:
GET /health
Resource Allocation
For production deployments:Summary
For OSS multinode deployments, the shared
config.json approach provides a simple, reliable way to keep all nodes in sync without the complexity of database synchronization.